Nols Ebersohn, Principal Architect and Certified Data Vault Trainer at Ignition (a Certus partner), outlines how to solve the issue of business keys that are NOT unique across the enterprise with the Data Vault methodology.
Business keys are a fundamental tenant of the Data Vault (DV) design and architecture. It is the backbone of the entire Data Vault integration efforts, as it makes it possible to link data across datasets and systems. Given the centrality of these keys to the DV idea, questions come up quite often. Probably the one I hear the most is:
In this article, I will outline different ways of addressing this challenge with the Data Vault methodology.
If you need more support with implementing and optimising Data Vault, reach out to the team at Ignition. Ignition are leading Data Vault experts, providing Data Vault training, Data Management Consulting, the Modern Data Platform Launchpad and Data Vault automation solution IRiS.
A business key usually uniquely identifies a thing within a system – like a customer, an account or a product. But what happens if the business key is not unique?
For example, a financial services organisation implements a home loan system for Australian customers by taking a copy of a system being used in Singapore. Instead of trying to shoehorn similar but diametrically opposed requirements into the same system, a copy of the platform is made and configured for the Australian jurisdiction. While this is operationally prudent from the banking platform perspective, it introduces the problem that the customer identifiers generated for Australian customers may be the same as those generated in Singapore. That means they are not unique across the enterprise. In fact, in the Australian platform, CustomerID=123, name=’Bob’ is clearly not the same as CustomerID=123, name=’Lee Chin’! However, they do have customers resident in both jurisdictions and therefore, must support a customer 360-degree perspective. Although the sequential surrogate keys assigned are unique within each copy of the platform, there is clearly no master data management occurring to prevent duplicates across two systems. Therefore, this business key collision will result in incorrect integration.
Now clearly, a reasonable person could expect that a modern digital business will have master data management principles and systems in place and that if mergers and acquisitions occur, integration efforts should be complete and thorough. A reasonable person would expect that synchronisation, matching and deduplication will happen, to make the business processes, as efficient as possible, through integration platforms (which there are many to choose from). A reasonable person could expect that all the business keys are managed across the enterprise to prevent this type of technical debt that hobbles the business process optimisation efforts. Sadly, the reasonable person is locked up in the asylum – who would have such ridiculous expectations?
The reality is that in most organisations disparate best-of-breed, off-the-shelf applications are used, and political, budgetary and project timeline constraints force tactical implementation decisions. Therefore, we should not be surprised to find that enterprise architectural principles are sacrificed for short term outcomes, resulting in what we call technical debt. An inconsistency between data in two systems must be solved when data gets to the Data Vault. Sadly, the eclectic set of vendors represented within your organisation do not have joint design sessions where these issues can be resolved – unless you force them (hard implementation requirements upfront) or hand over the appropriate small 3rd world country’s worth of GDP (post acquisition and deployment).

Returning to the problem at hand. How do we resolve the apparent business key collisions that result from this technical debt? For it is an integration technical debt – just to call the kettle black. In Data Vault, the problem of enterprise uniqueness can be dealt with by introducing an additional systems column to help provide a prefix/qualifier for each of the keys to make the key unique across the enterprise. Note that for this additional column/qualifier to work, it is imperative that it becomes an integral part of the key. By introducing this tie-breaker as an extension for each business key, we can manage the enterprise uniqueness.
Problem solved, you may think — nothing new here as it's a well-established approach even outside of the Data Vault context. Not quite. There are some traps for young players that need to be considered. These are explored below.
There are traps in the strategies employed to provide the necessary salting values. The challenge lies in the fact that some keys are, in fact, unique across the enterprise while other keys are sadly not unique across the enterprise.
Let’s look at a typical implementation strategy to set the scene and illustrate the problem (PLEASE NOTE –These examples are simplified representations, not complete DV structures. More comprehensive DV examples with all the recommended DV attributes are illustrated in the recommendations section at the end of this paper).

The usual strategy is to deal with this business key collision is to provide a qualifier.
Something akin to:
Side note: If you want to rename the BKCC to something that resonates more to your vernacular, by all means, feel free. However, if you adopt the functional intent of this technique, stick to the rules as outlined in this document.
This will then result in something looking like:

This approach outlines how to deal with the collision, where it exists for this singular key.
Let's further imagine that the product keys in both systems are, in fact, required to be the same for compliance and regulatory purposes – for instance, total mortgage exposure at an enterprise level. Fortunately, given the systems are copies of each other, this is incidentally the same. For example:

As this key is consistent across both systems, it provides a natural passive integration that we would benefit from integrating on this key, from a reporting and compliance perspective. Conversely, losing the integration for this key will have dire consequences.
All keys within each system are combined with the same system value. This works fine for the CustomerID as they require the salting to provide the uniqueness necessary.

However, this now introduces a problem on the ProductID, as the combined salting and values create two different instances where they were supposed to be ONE, as demonstrated below:

These newly salted business keys that were previously integrating correctly are now creating incorrect disparate keys and break the integration objectives.
The solution to this is fortunately readily available. Each business key must be evaluated in its own context for enterprise uniqueness as opposed at a global systems level. This allows the BKCC value to be defaulted to something like "ENT" (enterprise) as a designation. Only if a business key value collision does occur/exist, do we then specialise the BKCC value. Yes, the default expectation is that things are unique across the enterprise – optimistic indeed, but we live in hope.
This then corrects the introduced issue we observed with ProductID above and remains available to resolve the true collisions observed in CustomerID.

The other trap observed is the use of the Data Vault Record Source as the salting parameter. There are two issues with this approach. Both issues are related to a single column trying to fulfil two purposes. Information physics apply as with physical objects. No two objects can occupy the same space at the same point in time. Similarly, no column can serve two purposes at the same point in time. This is known as column overload, a very poor design.
1. Firstly, for salting to be suitable as demonstrated in the above examples, the record source will have to be very high level. This breaks the whole purpose of what the Record Source is supposed to be! A well-formed Record Source (RCSRC) should contain, at minimum, something akin to Instance.System.Schema.Table (e.g. AUS.Banking.Prod.Customer). This is the proper audit trial and intent of what Record Source’s purpose is.
Clearly, the more specialised the salting value, the less likely it will be that your DV will be able to integrate properly. This would mean that for every single time you encounter a key using the Record Source as the salting factor, it will result in a new bespoke key and the DV would have no Passive Integration – which would make it much more cumbersome to query and analyse. Remember, salting becomes an integral part of the key. So even if it originates from the same source system, it will produce spurious keys – demonstrated below:
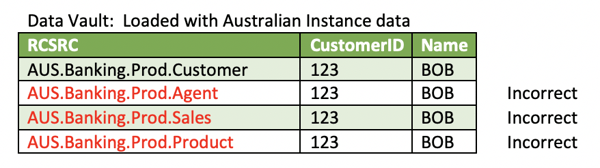
2. Since the CustomerID occurs in all four of the above tables, each one of them are recognised as different keys if RCSRC is the salting factor. The standard for DV is that we always load every business key value, irrespective of where it is encountered. This allows the DV to elegantly deal with:
3. On the flip side, if the RCSRC is only high level, the below results:

4. The above at least behaves in a way that the BKCC functionality requires. However, it devalues the RCSRC so that it fails to provide a proper audit trial of where the key originated from. This can be a real issue if a rogue key is detected and there is no way to track where it originated from. Perhaps a situation easy to deal with if you have only a few systems. However, many clients I have worked with have 110 systems with many tables utilising the same business keys. Manual searches in such situations are horrendous if not impossible – hardly delivering on the audit intent of Record Source.
5. Having said that, it is worth considering your RCSRC values when defining your BKCC values. In this instance, it is recommended to use AUS as the BKCC value rather than AU as it clearly aligns with the system identifier used in the Record Source.
6. Using the DV Record Source as a qualifying input will introduce a conditional process architecture that expresses itself as follows:

Firstly, let us agree on basic good design principles:
Separating BKCC and RCSRC allows each of the functional requirements to be performed without any cross-functional compromises. Let BKCC deal with resolving the enterprise uniqueness issues, and Record Source deal with the audit requirements at a suitably granular level to be effective for audit purposes.
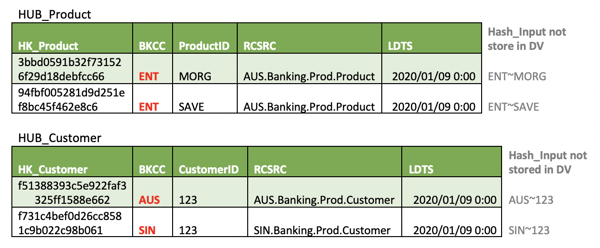
The structure of your Hub must record the business key as recognised and familiar to the business. Which part constitutes the business key in a hash input string is not familiar to the business. Following on from the above principle, let the business key be the business key, the BKCC deal with enterprise uniqueness concerns and the Record Source and load date-time stamps deal with the audit trial. Users will be able to understand what is being discussed when you have BKCC=AUS, CustomerID=123 rather than Customer=AUS~123.
This design approach provides the necessary robust framework to deal with the integration technical debt that business key collisions present. If hash keys are at all considered for the design and architecture of a Data Vault, it is highly recommended to adopt this approach. It deals with any business key collision issues at a per-key basis and provides a robust framework to future-proof the design as the BKCC is already included in the hash calculation. Implementing this retrospectively would require a recalculation of all hash keys across the design –something that should ideally be avoided.
Adopting this approach also guarantees that incorrect passive integration does not occur, safeguarding the fidelity and audit requirements within your Data Vault.
What does this then look like in standard structures? Below a few examples to set the context.
Note: for the below examples, the hash_input_strings are included for illustrative purposes – they are not part of the standard DV structure requirements.