
VM: This is a new offering from IBM called Virtual Data Pipeline. It's a virtual-physical appliance that lets you copy entire databases for the purposes of testing, development, and having backup and restore capabilities over those databases. It's designed to be user-friendly with self-service access to provisioning of data and to help reduce your costs across managing test data.
JH: A common problem that I’ve faced in data management and getting test processes done, both in departments that I’ve run and in helping clients with their processes, is that getting a hold of quality test data is difficult and subsequently looking after that data and keeping it synchronised with production is just as difficult - if not more so! Not to mention, maintaining multiple environments with all of this data in them is both complex and expensive.
VM: Half of the cost of testing is preparing the data and getting data ready for test cases so making this more efficient and streamlined is one of the key areas for reducing costs. Hardware costs, networking costs and costs associated with setting up administrators and test environments are also important considerations to make.
The problem we’re trying to solve with Virtual Data Pipeline is how to provision all of these non-production environments more efficiently in order to get to testing earlier and achieve better testing outcomes.
VM: I'll give you a basic example. What the virtual data pipeline is doing is using its appliance to copy the entire database from a source system over into the storage of the appliance using some of the native backup and recovery functions of databases like Oracle SQL server and DB2. It then takes this copy and turns it into a gold copy that is forever incrementally updated and creates virtual copies of it for development testing, user acceptance testing (UAT) and so on. Each virtual copy doesn't need to take up any additional disk space or database licensing: it is a virtual copy of the entire database with optional data masking added to it. It's designed to give you very fast self-service access to full copies of databases off the appliance itself.
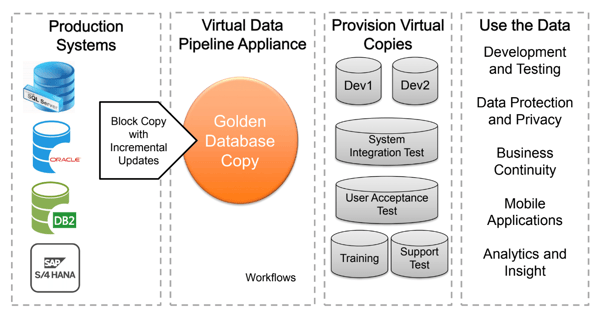
First, it doesn't require me to always have developers building out a set of data each time I want a copy for UAT and secondly, I also don't need to deal with the synchronization problem associated with keeping data and data structures up to date.
Want to find out how VDP can work for your DevOps team? Get in touch with us at datawarehousing@certussolutions.com or find out more via the webinar we created discussing Virtual Data Pipeline and its use cases https://www.certussolutions.com/virtual-data-pipeline-webinar
