
Vincent McBurney and I recently sat down to talk about Virtual Data Pipeline and what it can help with. This blog forms part of a five-part Q+A series. This blog covers how to set up VDP, following the other blogs which have covered what Virtual Data Pipeline is, Data Fabrication & Data Masking with Virtual Data Pipeline and Cloud-based Data Warehousing with VDP, including the implications of GDPR.
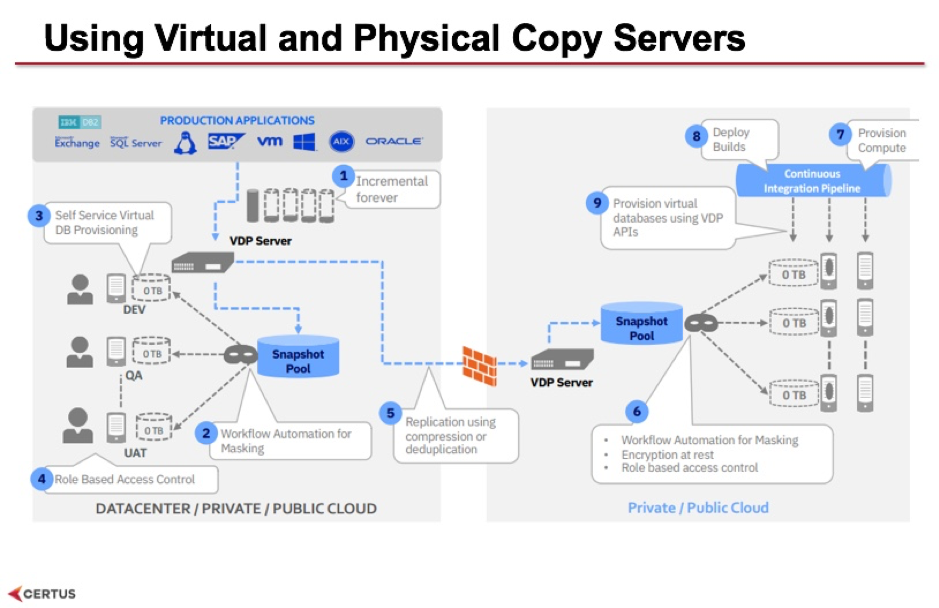
This slide shows where the physical devices sit. The gold copy, and all other copies of the data, is stored onto an appliance. This could be a virtual appliance - you can install it on to your own server and the virtual software will take care of all of the storage of data and the running of the VDP software, and you can install one on your premises to directly access your database applications that are on prem. Then you can have another appliance that gets installed on your cloud - this one can be the the physical appliance, because it's available in most data centres, and this one will receive a replication of the data from your premises on to the cloud.
You still need to go through the steps outlined on this diagram such as:
Then users can come and start using the self-service functions so that they can provision their environments and access them. Once they’re set up, the virtual copies are available just like any other database so your applications will access them as though they were the original database themselves. In a data warehouse scenario, data load tools will access them through ODBC or JDBC connectors to get the data out and put it into the data warehouse. BI, reporting and analytics tools can use the same methods to pull data.
To most of your applications there’s no difference – it’s as though they're accessing the original databases themselves, only you're not having direct access to a production system or impacting a production system, you're accessing a copy of that data.
Yes. Each virtual data copy is a pointer back to the original gold copy so you're not creating new copies of it, you're just pointing at the original copy. They are read/write copies so if you do make changes, if want to load test data or write test cases back again, then it’s stored locally on the device as extra storage. But you can also use the clone function which creates a complete static copy of the data. It doesn't require database licensing but it is another copy of the gold data. Otherwise you can do a live copy which gives you a copy of the data that's your own copy, which is automatically updated from the gold copy once data refreshes come through. So you've got multiple ways of deciding how you're going to create your own copy of the data and use that copy.
Want to find out how VDP can work for your DevOps team? Get in touch with us for a proof of concept at datawarehousing@certussolutions.com.
If you’d like to find out more, watch the webinar Vincent and I created discussing Virtual Data Pipeline and its use cases https://www.certussolutions.com/virtual-data-pipeline-webinar
