
Vincent McBurney and I recently sat down to talk about Virtual Data Pipeline and what it can help with. This blog forms part of a five-part Q+A series. This blog covers use cases for VDP.
This is a design for an improved data warehouse in the cloud using data copy, instead of data loads and data replication. We've got the device on-prem pulling data from applications and copying it into that local device which could be a virtual application. Then we have the copy synchronized from the premises, through the firewall, to the Microsoft Azure cloud. This is parallel loaded with compression for a faster and lower-cost copy into the cloud environment meaning we have a perfect copy of source databases on the cloud environment.
Unlike a previous replication to S3 data buckets, we now have access to the copy of the original business databases and we can copy the data straight into our Data Vault using any of the tools on Azure such as data refinery, data bricks or ETL tools. Once it’s in our Data Vault we can start processing that data on the Data Vault creator presentation layer and get our reports and analytics populated with regularly refreshed data.
We can set service level agreements back inside the appliance on how often we take copies and how often we refresh the data eg. every hour or every two hours. We can set different policies and different service level agreement for different source systems. Our Data Vault can accept data at different intervals and accept late-arriving data.
Essentially we can use this as a copy tool to get the data on to the cloud and then use it on the cloud to:
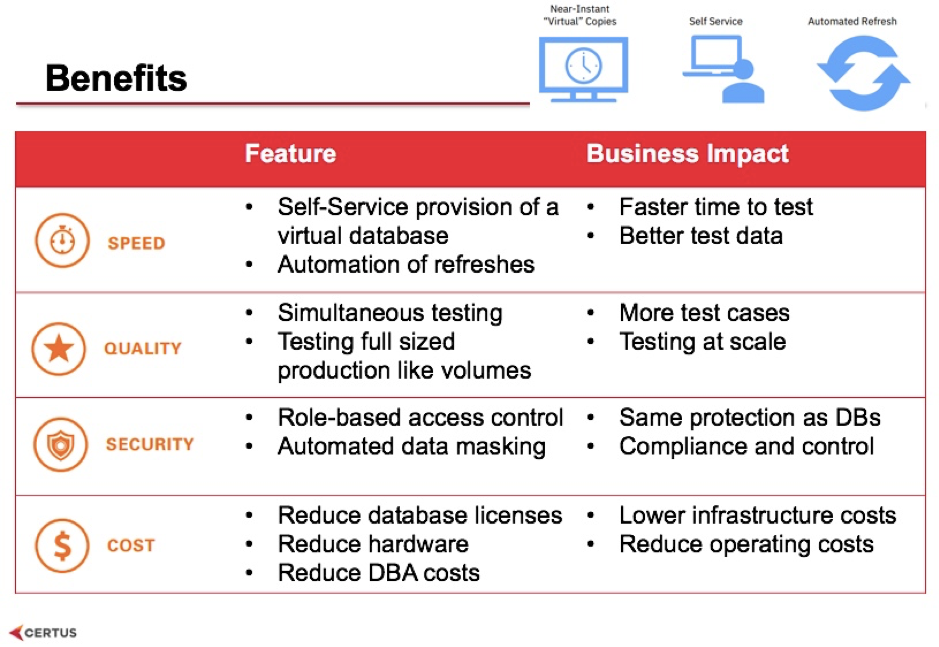
That's one of the big cost savings because normally development environments are trimmed down for the sake of testing more quickly or saving money on hardware. However with Virtual Data Pipeline you can create a full-sized environment almost instantly for development unit testing, functional testing, performance testing, system integration testing and so on. Any developer can use the self-service tools and create their own full test environment to run a test against full-size production data. The testing team can do the same thing and you're not paying for another copy of the database. You’re provisioning it as a virtual copy and getting access to that data instantly so it is a huge saving if you're trying to run test cases against full-sized data.
Want to find out how VDP can work for your DevOps team? Get in touch with us for a proof of concept at datawarehousing@certussolutions.com.
If you’d like to find out more, watch the webinar Vincent and I created discussing Virtual Data Pipeline and its use cases https://www.certussolutions.com/virtual-data-pipeline-webinar
