
Vincent McBurney and I recently sat down to talk about Virtual Data Pipeline and what it can help with. This blog forms part of a five-part Q+A series, with previous discussion focusing on "What is Virtual Data Pipeline?" and "Data Fabrication & Data Masking with Virtual Data Pipeline". In today's blog, we discuss GDPR and cloud-based data warehousing with Virtual Data Pipeline.
So: in a real life situation if I have my Data Vault warehouse in the cloud, how would how would I actually use it when I wanted to execute that testing?
We looked at a use case of how to do analytics in the cloud and how to move the data off on-premises into that cloud. We do this in our solution offering called Iris, which is a Data Vault data warehouse on Azure. What we're looking to do with Virtual Data Pipeline is to get the initial data copy from the business applications databases on premises and drop them into a local copy of VDP appliance. That lets you use those local copies to do your testing of those applications such as upgrade testing, migration testing, and then to do a synchronization of the on-premises appliance to the cloud-based appliance.
This is one of the things that VDP can do: synchronize the data between two appliances. It can use encryption, deduplication and compression before it makes the copy so that you have a very efficient copy between appliances and it can run the copy and that synchronization in parallel. As such, you can scale this up to multi-terabyte databases and you'll be copying the data from your on-premises appliance through the firewall into a cloud server and onto the appliance sitting on the cloud.
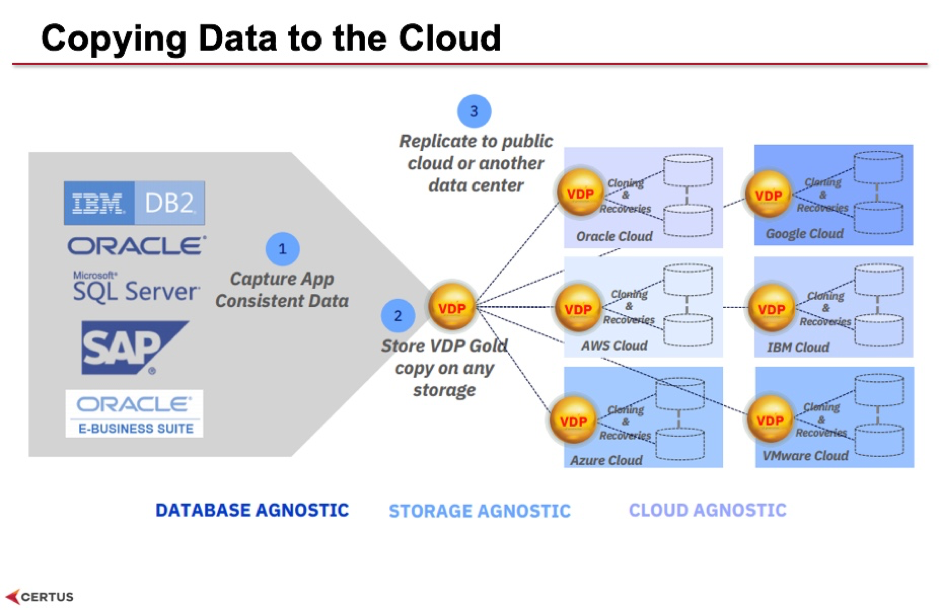
You can see on the cloud diagram that we can copy onto AWS or Google cloud or IBM cloud or Microsoft Azure cloud - you can put your target appliance on to any cloud! Our Iris application sits on Microsoft Azure.
So what VDP can enable is that we can get an exact copy of the database available to us on the cloud. This gives us access to all the original records in their original format, both untranslated and unchanged, which is exactly what a Data Vault data warehouse is trying to do. It's trying to receive the original records and store them in a broad Data Vault so that we have an audit trail, and the original data, available to us to see what the data looks like at any point in time.
What VDP will do is pass a workflow over to a masking server and let you mask the data before it's provisioned out through any of these virtual copies. This is why IBM has added it to the test data management suite. It can pass the request to Optim data masking which can mask things like email addresses, names, phone numbers; it can replace those values with substitute data, encrypted values or form a space; and then it can provision the masked version across to your virtual copies. On those virtual copies you add in your normal role-based security which indicates who's allowed to look at what. As such, you get the same role-based security you would get from the original database.
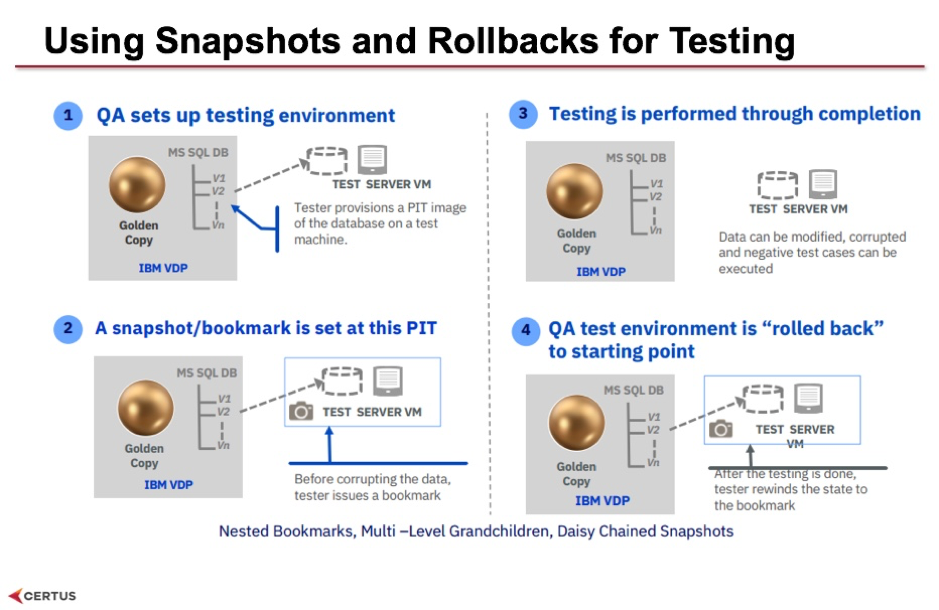
What we're looking at here is the ability to take a point-in-time snapshot of the gold copy and set it up for testing purposes. Then to add your test data to that to set up your specific test scenarios and turn that into a snapshot that you can roll back to. You then run your tests – in our Iris data warehouse scenario, our tests might involve running full loads into the database or running incremental batches and it might change the data. If we're doing failure testing we might erase tables or we might erase entire schemas to see how the loads handle that in fail-over recovery. Once we’re done we can roll the tests back to its original snapshot starting point so that we can fix the code and run the test again. So this snapshot capability in a data warehouse scenario lets us replay and run tests continuously through our sprints which is exactly what we want to do in an agile environment.
Exactly - a data scientist can use the self-service function to go in and request a clone of the entire database for their data science workbook. They can take that clone, a complete copy of the database, on demand or they can take a virtual copy and they can choose that to be at a point in time and create their own snapshots from that. Then they can run their algorithms and their data science worksheets against that data. A data scientist might ask for a clone of the data that hasn't been masked so that they can do data mining to spot patterns in the data so they're essentially creating an on-demand discovery environment. They can take a discovery environment off the source data or we can create gold copies and snapshots of the warehouse itself and they can run data discovery against the data warehouse itself.
Want to find out how VDP can work for your DevOps team? Get in touch with us for a proof of concept at datawarehousing@certussolutions.com.
If you’d like to find out more, watch the webinar Vincent and I created discussing Virtual Data Pipeline and its use cases https://www.certussolutions.com/virtual-data-pipeline-webinar
